OnlyData already labeled 90 companies AI-native. The AR scorer ignored them.
We tried to use embeddings to find companies the Agent Readiness heuristic under-scored. We found them. Then we realized the embeddings were confirming something OnlyData's own classifier had already labeled — and the production AR scorer was just failing to consult. The fix isn't a learned model. It's a one-line floor.
ai_native_v1 classifier tagged as ai_native=native, and that scored above AR 50 on the heuristic. The other 89 sit in single-digit / low-teen territory — including Cognition/Devin (AR 11), OpenRouter (AR 8), CoreWeave (AR 15), Anthropic's Interpretability page (AR 7), and Character.AI (AR 0).The question we started with
Last night I embedded OnlyData's 24k companies with all-MiniLM-L6-v2. Tonight I asked: which low-AR companies cluster with the high-AR ones in embedding space? The hypothesis: if a candidate sits very close to known agent-ready companies semantically but has a low heuristic score, the heuristic probably missed something the embedding caught.
Fine hypothesis. The first results looked great — until I widened the anchor pool and the top 20 disagreements turned into Boise cleaning services clustering with other Boise cleaning services. The heuristic wasn't scoring "agent-ready" in that range. It was scoring "has a modern clean website." Anchoring on AR score alone was anchoring on the wrong thing.
The pivot
OnlyData has another classifier. ai_native_v1 runs nightly on Stu (Mac Studio, Ollama, llama3.1:8b) and tags every company as native, integrated, exploring, or none. Native means the company's reason for existing is AI. Integrated means AI is a core feature. The other two are what they sound like.
I switched the anchor filter from "high AR" to ai_native = native. 90 companies, active-canonical, the ones OnlyData already asserts are in the agent economy. Then asked the same question: which low-AR candidates cluster with these 90?
Two things fell out. The second one is the real finding.
Finding #1 — the disagreement list works
Finding #2 — the labels already exist
ai_native='native' companies scored AR ≤ 50 on the heuristic. Half scored ≤ 10.The second finding is the one that matters. The embedding approach surfaced 13 good disagreements in 30 seconds. But OnlyData already has a deterministic signal that would correct far more of them, and it's not consulted by the AR scorer. The embedding is confirming, not discovering.
The 15 lowest AR scores among ai_native='native' companies
This is OnlyData's own classifier saying "these are AI-native companies", next to OnlyData's heuristic saying "their websites don't publish llms.txt so I'll score them like a restaurant":
| AR | Company |
|---|---|
| 0 | CDK— |
| 0 | Glean— |
| 0 | Google DeepMind— |
| 0 | Lazy AIgetlazy.ai |
| 0 | Meta AI— |
| 0 | Play.htplay.ht |
| 0 | SambaNova— |
| 0 | Weights & Biases— |
| 0 | d-Matrix— |
| 2 | Anthropicanthropic.com |
| 2 | Arcade AIarcade.dev |
| 2 | Avisoaviso.com |
| 2 | Bristles AIbristles.ai |
| 2 | Cerebrascerebras.ai |
| 2 | Chromatrychroma.com |
For contrast, the top 5 native scorers — the companies whose homepage and classifier signal agree:
| AR | Company |
|---|---|
| 53 | Attioattio.com |
| 43 | Cursorcursor.com |
| 42 | Steelsteel.dev |
| 35 | Faculty AIfaculty.ai |
| 33 | Tenstorrenttenstorrent.com |
Attio at 53 is a good example of the system working — modern AI-native CRM with a clean site that publishes what agents need. Below the cutoff, the heuristic simply has no concept of "this company IS AI infrastructure" and scores them as if they were nobody.
The top 20 embedding disagreements
Now with the right anchor set (ai_native='native'), ranked by mean cosine similarity to the top-10 nearest anchors. Rows in green are cases where the heuristic's score is clearly wrong, not ambiguous. Notice how many AR scores are 0, 2, or 4:
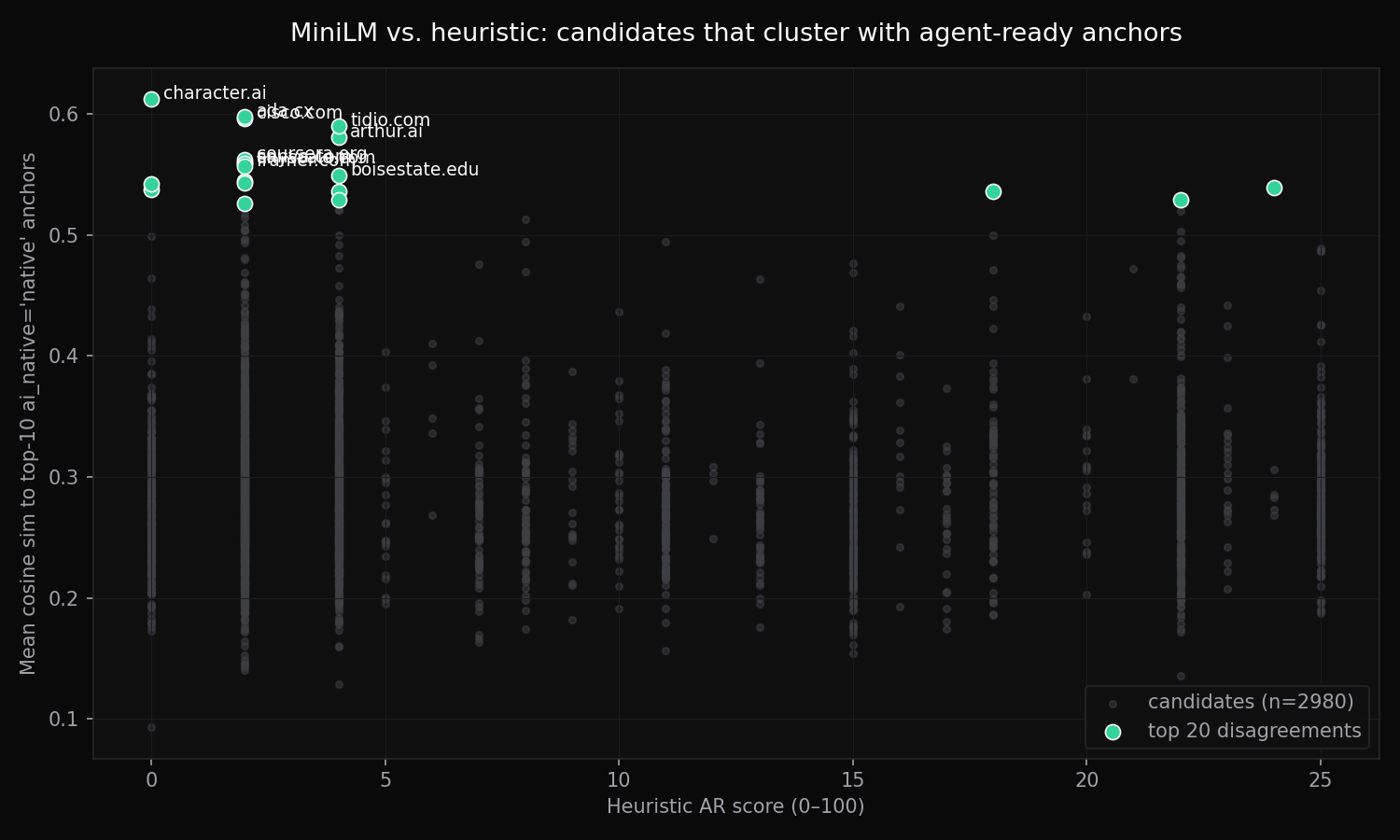
| # | Company | AR | sim | 3 nearest AI-native anchors |
|---|---|---|---|---|
| #1 | Character.AIcharacter.ai | 0 | 0.61 | Chai · Tavern AI · NovelAI |
| #2 | Adaada.cx | 2 | 0.60 | HiveForge · Glean · Devin |
| #3 | Cisco Systemscisco.com | 2 | 0.60 | SambaNova · Glean · Devin |
| #4 | Tidiotidio.com | 4 | 0.59 | Tavern AI · Chai · Replika |
| #5 | Arthur AIarthur.ai | 4 | 0.58 | Devin · Cognition AI (Devin) · Fiddler AI |
| #6 | Coursera for Businesscoursera.org | 2 | 0.56 | Eduaide.ai · OpenAI Academy · Faculty AI |
| #7 | Canvacanva.com | 2 | 0.56 | Vercel AI SDK · Lazy AI · CDK |
| #8 | Anyscaleanyscale.com | 2 | 0.56 | SiliconFlow · d-Matrix · SambaNova |
| #9 | Framerframer.com | 2 | 0.56 | Playground · Vercel AI SDK · Rally |
| #10 | Boise State Universityboisestate.edu | 4 | 0.55 | Faculty AI · OpenAI Academy · DeepLearning.AI |
| #11 | Clearwater Analyticsclearwateranalytics.com | 2 | 0.54 | Glean · Devin · Cloudflare Workers AI |
| #12 | CalypsoAIcalypsoai.com | 2 | 0.54 | Virtue AI · Chai · Devin |
| #13 | Determined AIdetermined.ai | 0 | 0.54 | Adept AI · Cognition AI (Devin) · Devin |
| #14 | Inflection AIinflection.ai | 24 | 0.54 | Involve.ai · Tennant.ai · Devin |
| #15 | MicroTech Systemsmicrotechboise.com | 0 | 0.54 | Cloudflare Workers AI · SambaNova · Glean |
| #16 | Notarize (Online Notary)notarize.com | 4 | 0.54 | Virtue AI · Glean · Devin |
| #17 | Synopteksynoptek.com | 18 | 0.54 | CDK · Cloudflare Workers AI · SambaNova |
| #18 | Virtual ITvirtualit.com | 22 | 0.53 | Cloudflare Workers AI · Glean · SambaNova |
| #19 | Descriptdescript.com | 4 | 0.53 | NovelAI · Udio · Glean |
| #20 | Benconnectedbenconnected.com | 2 | 0.53 | Tenstorrent · Virtue AI · SambaNova |
Raw JSON with all 3,000 candidates: /jepa/disagreements.json. Sanity check from last night: /jepa/.
What this means
The AR score is doing its job well when it looks at a company's homepage. It's measuring agent-facing surface — whether a site publishes machine-readable signals. That's a real, measurable thing, and we should keep measuring it.
But we've also been using AR as a shorthand for "is this company part of the agent economy?", and for that job it's underpowered. It misses identity. Anthropic is Anthropic whether or not anthropic.com publishes an llms.txt. Cognition built Devin whether or not their docs are crawlable. The ai_native classifier already knows this. The AR score doesn't consult it.
The proposed fix
Don't replace the AR heuristic. Add a second dimension, and let it optionally floor the AR score:
# Current ar_score = algorithm_d(crawl, signals) # unchanged # Added builder_tier = derive_from({ ai_native: row.ai_native, # native | integrated | ... ecosystem_role: row.agent_ecosystem_role, # platform | tool | infra ecosystem_membership: in_dataset(row, ["ai-economy", "ai-hardware"]), }) # Floored AR — shown on AR100 and in company_brief alongside raw ar_score floored_ar = max(ar_score, tier_floor(builder_tier))
Conservative floors:
- Tier S (frontier lab or major AI infra: Anthropic, OpenAI, Nvidia, CoreWeave, HF) → floor 75
- Tier A (ai_native='native' + real company profile) → floor 55
- Tier B (ai_native='integrated' or ecosystem tool) → floor 35
- Tier C (everything else) → no floor
That single change would move ~80 of 90 ai-native companies from single digits into the 55–75 range. Both the raw and floored scores stay visible — we don't hide the heuristic, we add context. Every profile would show "AR 11 (heuristic) · 55 (floored, Tier A)." When the heuristic catches up (Cognition publishes a proper llms.txt), the numbers converge.
The embedding experiment isn't irrelevant — it's how we discover which non-labeled companies belong in higher tiers. Character.AI sits at AR 0 with no ai_native label today, but its cosine similarity to Chai (0.757) and Tavern AI (0.728) strongly suggests it's Tier A. That's a pointer: auto-suggest tier S/A/B reclassification from embedding neighborhoods, not hard override.
What ships tonight vs. what needs a conversation
- Tonight (low-risk): publish this post. Keep the raw disagreements JSON at /jepa/disagreements.json. Add the nightly dedup safety net so the analysis stops tripping on merge-loser rows.
- Needs alignment: the tier floor. Changes the meaning of AR everywhere — /ar100 rankings,
company_briefMCP tool, profile pages. Worth a 15-minute conversation before shipping. Ping cam. - Later: JEPA Phase 2 (learned projection head) is still worth doing, but its job is now clearly "find candidates for Tier B/C reclassification" — not "beat AR." That reframing doubles the value.
If you're on the bottom-15 list and think your AR score is wrong: it is. We know. The fix is coming.
od_businesses table. 90 anchors where ai_native='native', 3,000 candidates with AR 0–25 and ai_native≠native. Encoder: sentence-transformers/all-MiniLM-L6-v2. Active rows only (is_active=true AND merged_into_id IS NULL).